Po-Chen KoSeeking for PhD position 2026 Fall! I obtained my Bachelor's degree 2024 Summer at National Taiwan University, advised by Prof. Shao-Hua Sun. I am interested in Computer Vision, Machine Learning, Robotics and Reinforcement Learning. I was fortunate to visit Josh Tenenbaum’s lab at MIT in 2023 Spring semester, collaborating with Jiayuan Mao and Yilun Du on Learning to Act from Actionless Video through Dense Correspondences. |
|
ResearchI am currently exploring video generative models as control policies for robotics. |
|
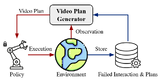
Implicit State Estimation via Video ReplanningPo-Chen Ko, Jiayuan Mao, Yu-Hsiang Fu, Hsien-Jeng Yeh, Chu-Rong Chen, Wei-Chiu Ma, Yilun Du, Shao-Hua Sun Under Submission ICML Workshop on Building Physically Plausible World Models 2025 (Best paper) paper We develop an adaptive video-based planning system that incorporates interaction-time feedback to handle uncertainty. By refining its latent state representation and filtering out failed plans, the framework adapts without explicitly modeling hidden parameters. Tested on a new manipulation benchmark, it significantly improves replanning and robustness in video-driven control. |
|
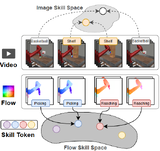
Learning Skill Abstraction from Action-Free VideosHung-Chieh Fang*, Kuo-Han Hung*, Chu-Rong Chen, Po-Jung Chou, Chun-Kai Yang, Po-Chen Ko, Yu-Chiang Wang, Yueh-Hua Wu, Min-Hung Chen, Shao-Hua Sun Under Submission ICML Workshop on Building Physically Plausible World Models 2025 paper We develop a framework that learns and composes robot skills directly from action-free videos using optical flow as an action substitute, enabling skill-space planning and strong multitask and long-horizon performance without labeled data. |

|
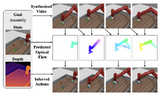
Context-Aware Replanning with Pre-Explored Semantic Map for Object NavigationPo-Chen Ko*, Hung-Ting Su*, Ching-Yuan Chen*, Jia-Fong Yeh, Min Sun, Winston H. Hsu CoRL 2024 paper / arxiv / website We improved VLM-based semantic maps for Object Navigation by leveraging uncertainty information from the map to aid candidate selection. |
|
Learning to Act from Actionless Video through Dense CorrespondencesPo-Chen Ko, Jiayuan Mao, Yilun Du, Shao-Hua Sun, Joshua B. Tenenbaum ICLR 2024 (Spotlight) paper / arxiv / video / website / code We developed a robot policy using images, which can be trained without action annotations. It’s trained on RGB videos, effective for table-top tasks and navigation. Our framework also allows rapid modeling with just 4 GPUs in a day. |
Awards & Achievements |
NTUEE Undergraduate Innovation Award1st. prize / Department-wide AVDC open-source video-planner training library200+ GitHub stars NTU ML2021Spring Speaker Classification Competition1st Place / 1170 participants |
|
Design and source code stolen from Jon Barron's website |